0 Abstract
교차 엔트로피 손실에 대한 언어 모델 성능에 대한 경험적 스케일링 법칙을 연구합니다. 손실은 모델 크기, 데이터 세트 크기 및 훈련에 사용되는 컴퓨팅 양에 따라 거듭제곱 법칙으로 확장되며 일부 추세는 7자릿수 이상에 걸쳐 있습니다. 네트워크 폭이나 깊이와 같은 기타 아키텍처 세부 사항은 넓은 범위 내에서 최소한의 영향을 미칩니다. 간단한 방정식은 모델/데이터 세트 크기에 대한 과적합의 의존성과 모델 크기에 대한 훈련 속도의 의존성을 제어합니다. 이러한 관계를 통해 고정 컴퓨팅 예산의 최적 할당을 결정할 수 있습니다. 모델이 클수록 샘플 효율성이 훨씬 더 높아집니다. 따라서 최적의 계산 효율성을 갖춘 교육에는 상대적으로 적당한 양의 데이터에 대해 매우 큰 모델을 교육하고 수렴 전에 상당히 중지하는 작업이 포함됩니다.
1 정리
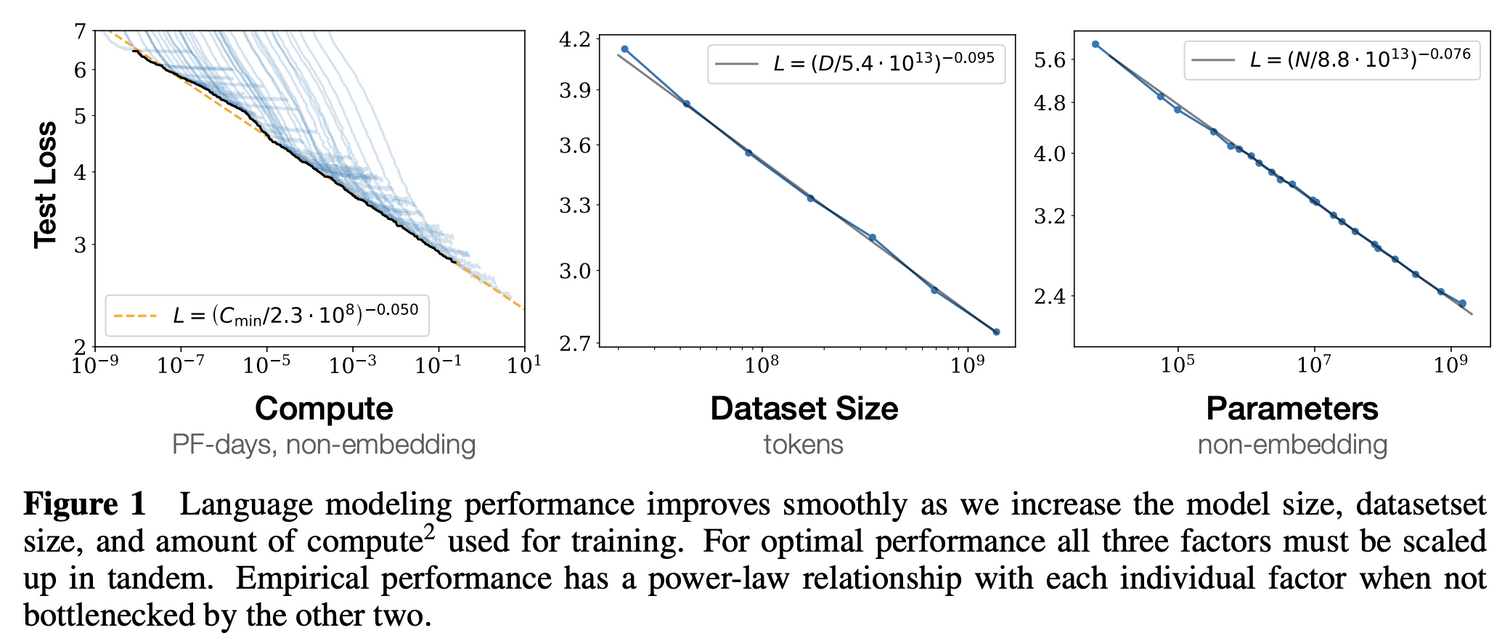 데이터셋과 모델의 크기, 계산 성능에 따른 loss의 감소는 멱법칙을 따른다.
또한, computing efficient한 방법은 수렴하는 loss에 한계가 있다.
데이터셋과 모델의 크기, 계산 성능에 따른 loss의 감소는 멱법칙을 따른다.
또한, computing efficient한 방법은 수렴하는 loss에 한계가 있다.
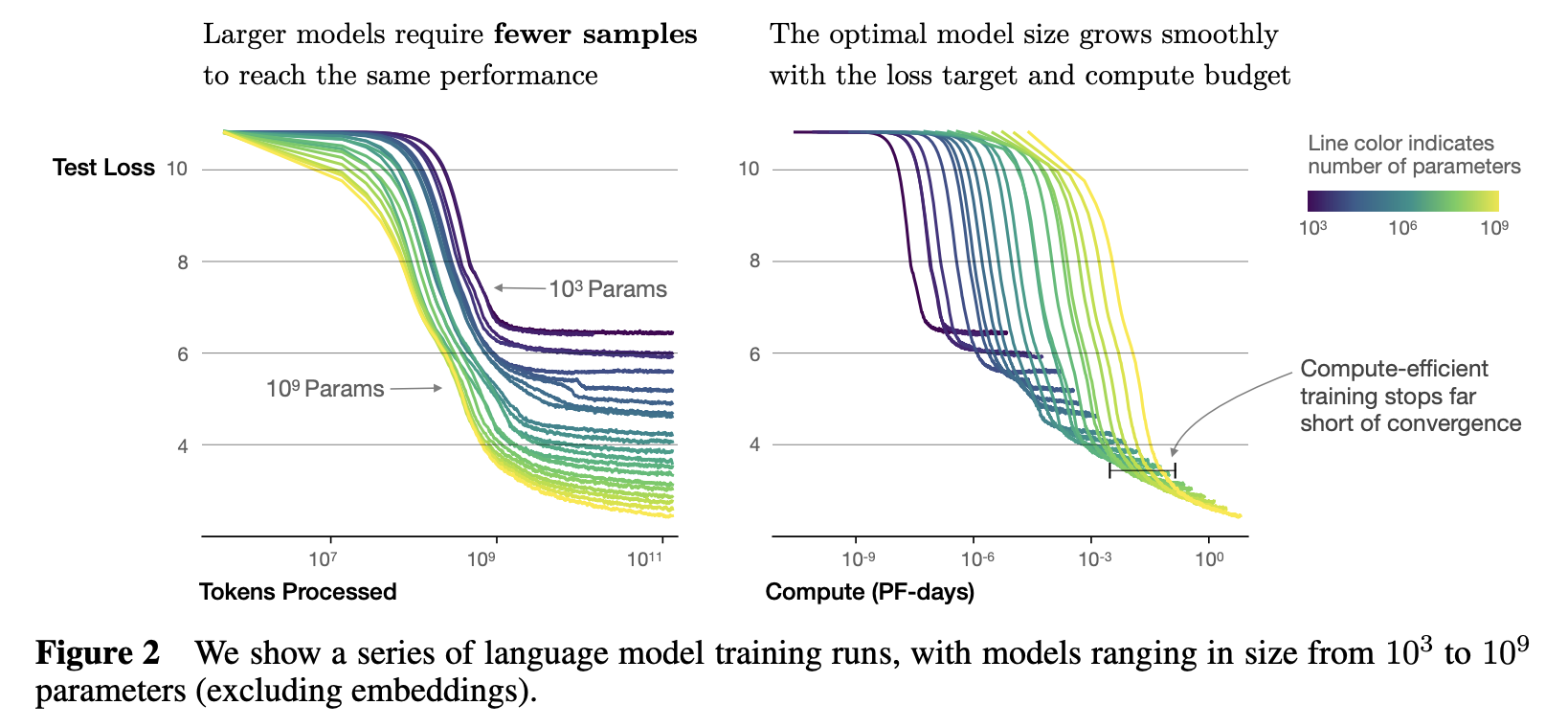 Large model 은 Small model에 비해 sample-efficient 하여, 더 적은 step과 data point를 통해 비슷한 수준의 성능에 도달할 수 있다.
Large model 은 Small model에 비해 sample-efficient 하여, 더 적은 step과 data point를 통해 비슷한 수준의 성능에 도달할 수 있다.
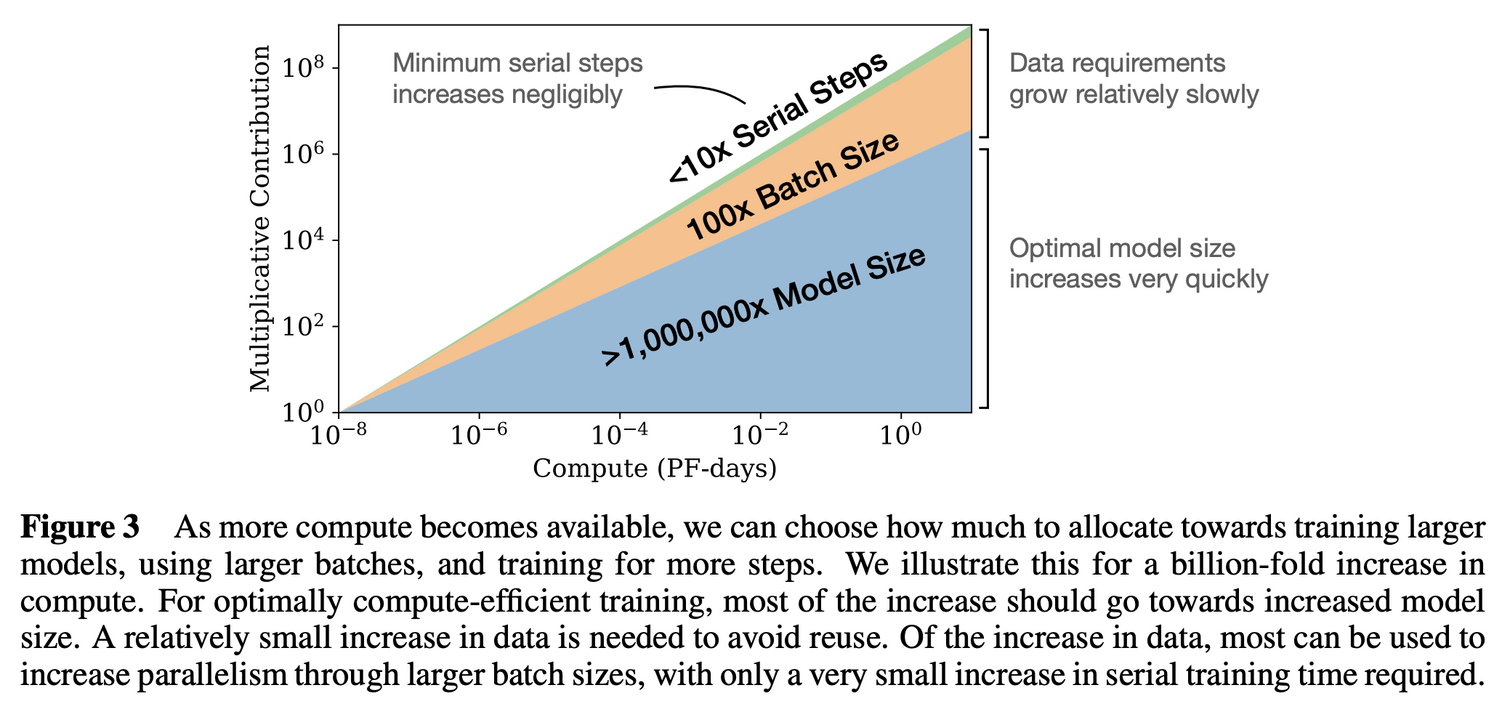 compute budget에 따른 성능에 영향을 미치는 요인들의 비중
compute budget에 따른 성능에 영향을 미치는 요인들의 비중
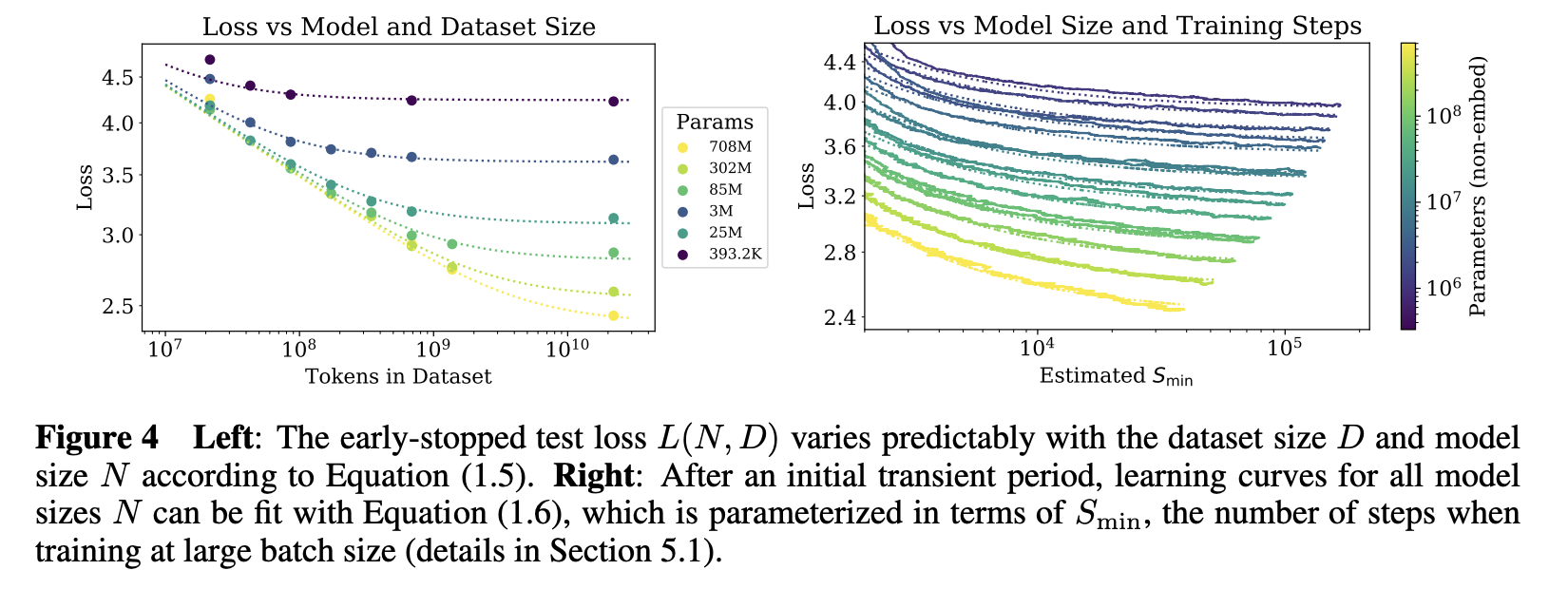 step에 따른 training loss는 모델 및 데이터셋의 크기에 따라 어느정도 예측 가능하다.
step에 따른 training loss는 모델 및 데이터셋의 크기에 따라 어느정도 예측 가능하다.
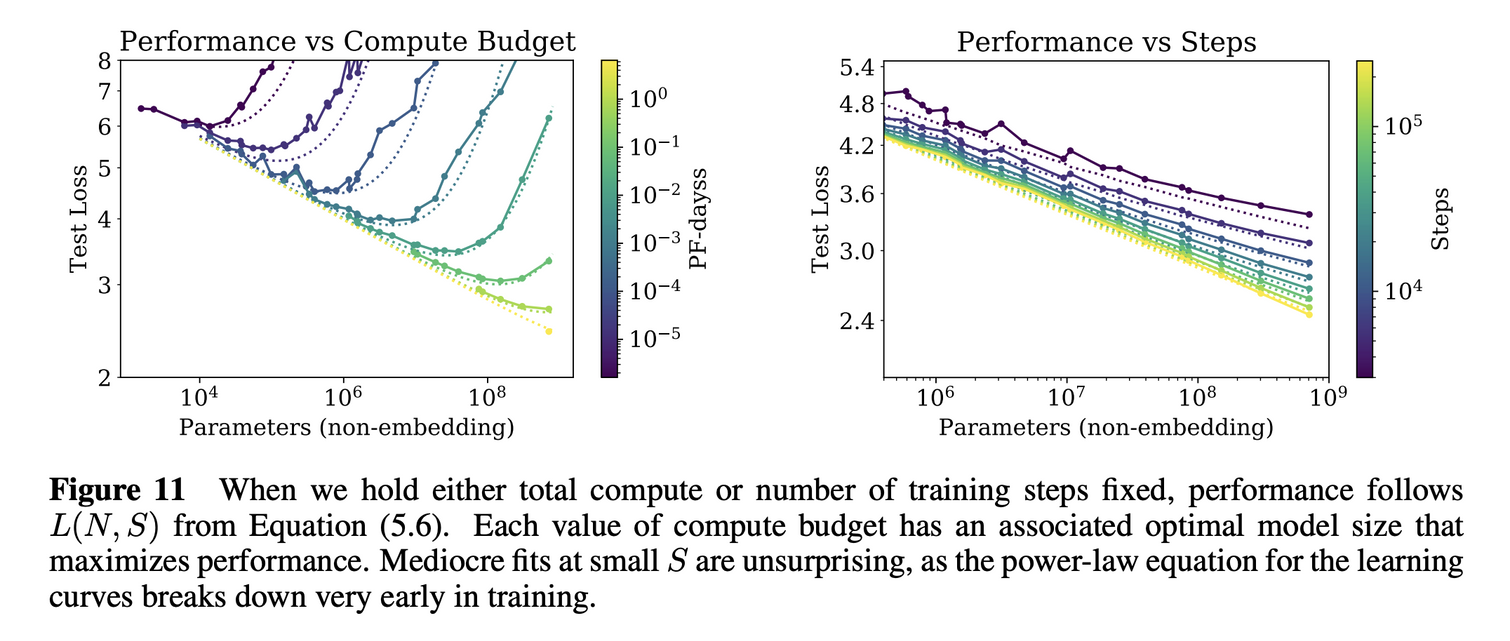 test loss에 대한 training curve는 모델의 크기에 관계없이 power law로 어느정도 예측 가능하다.
test loss에 대한 training curve는 모델의 크기에 관계없이 power law로 어느정도 예측 가능하다.