1 Abstarct
훈련 세트 크기, 모델 크기 또는 둘 다의 힘으로 오류가 감소하는 널리 관찰된 신경 확장 법칙은 딥 러닝의 상당한 성능 향상을 가져왔습니다. 그러나 확장 자체를 통한 이러한 개선에는 컴퓨팅 및 에너지 측면에서 상당한 비용이 필요합니다. 여기에서는 데이터 세트 크기에 따른 오류 스케일링에 초점을 맞추고, 순서를 매기는 고품질 데이터 정리 메트릭에 액세스할 수 있는 경우 이론적으로 어떻게 멱법칙 스케일링을 넘어 잠재적으로 지수 스케일링으로 줄일 수 있는지 보여줍니다. 정리된 데이터 세트 크기를 얻으려면 훈련 예제를 삭제해야 합니다. 그런 다음 경험적으로 정리된 데이터 세트 크기를 사용하여 이 향상된 스케일링 예측을 테스트하고 실제로 CIFAR-10, SVHN 및 ImageNet에서 훈련된 ResNet에서 실제로 거듭제곱 법칙 스케일링보다 더 나은 것을 관찰합니다. 다음으로, 고품질 가지치기 지표를 찾는 것이 중요하다는 점을 고려하여 ImageNet에서 10가지 데이터 가지치기 지표에 대한 최초의 대규모 벤치마킹 연구를 수행합니다. 대부분의 기존 고성능 메트릭은 ImageNet에 비해 확장성이 떨어지는 반면, 가장 좋은 메트릭은 계산 집약적이며 모든 이미지에 레이블이 필요합니다. 따라서 우리는 최고의 감독 지표와 비슷한 성능을 보여주는 간단하고 저렴하며 확장 가능한 새로운 자체 감독 가지치기 지표를 개발했습니 다. 전반적으로, 우리의 연구는 좋은 데이터 정리 측정항목의 발견이 실질적으로 향상된 신경 확장 법칙을 향한 실행 가능한 경로를 제공하여 현대 딥 러닝의 리소스 비용을 줄일 수 있음을 시사합니다.
2 정리
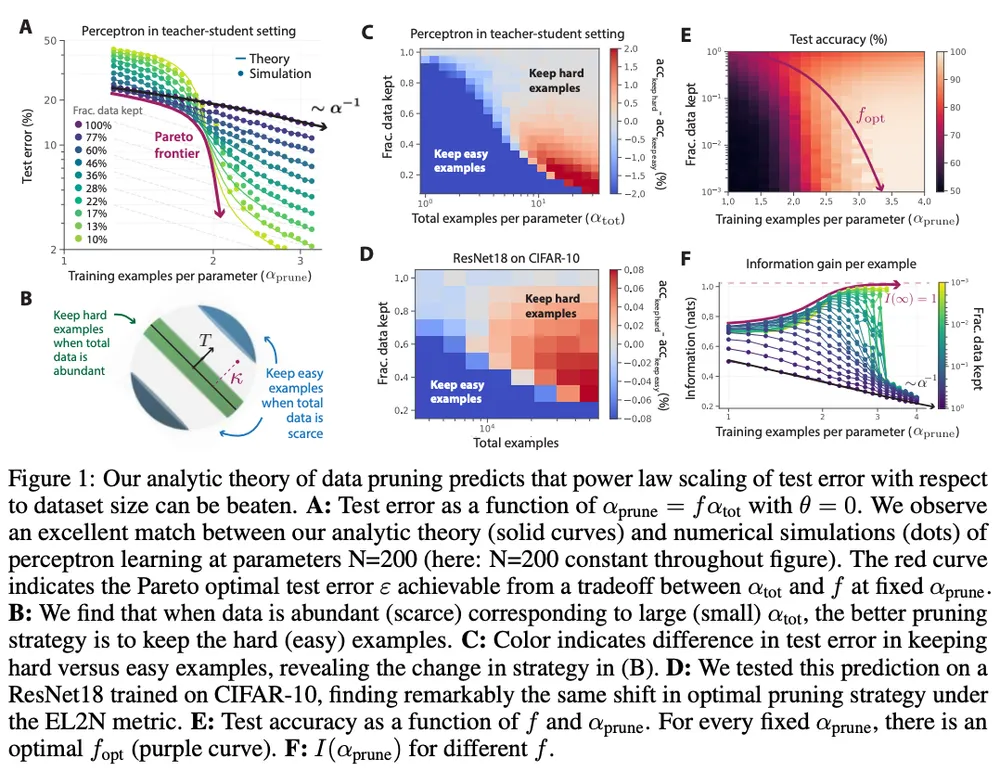 90%의 데이터를 pruning하여 높은 성능을 얻음. 대부분의 데이터는 오히려 noise처럼 작용하여 학습에 해로운 영향을 끼친다.
90%의 데이터를 pruning하여 높은 성능을 얻음. 대부분의 데이터는 오히려 noise처럼 작용하여 학습에 해로운 영향을 끼친다.